文章地址:
标题:Federated Learning in Mobile Edge Networks: A Comprehensive Survey
发表会议:
[toc]
Privacy and Security Issues
FL的主要目标之一是保护参与者的隐私,即,参与者只需要共享训练模型的参数,而无需共享他们的实际数据。 但是,最近的一些研究工作表明,当FL参与者或FL服务器本质上是恶意的时,可能会引起隐私和安全问题。 尤其是,这会破坏FL的目的,因为生成的全局模型可能会损坏,或者在模型训练期间甚至可能损害参与者的隐私。 在本节中,我们讨论以下问题:
- Privacy: 即使FL不需要为协作模型训练而交换数据,恶意参与者仍可以根据其他参与者的共享模型来推断敏感信息,例如性别,职业和位置。 例如,在[152]中,当在FaceScrub [153]数据集上训练二元性别分类器时,作者表明,他们可以仅通过检查共享模型来推断出某个参与者的输入是否包含在数据集中, 精度高达90%。 因此,在本节中,我们讨论与FL中的共享模型有关的隐私问题,并讨论为保护参与者的隐私而提出的解决方案。
- Security: 在FL中,参与者在本地训练模型并与其他参与者共享训练后的参数,以提高预测的准确性。 但是,此过程容易受到各种攻击,例如数据和模型中毒(data and model poisoning),在这种攻击中,恶意参与者可能会发送不正确的参数或损坏的模型,从而在全局聚合期间伪造学习过程。 因此,全局模型将被错误地更新,并且整个学习系统将被破坏。 本节讨论有关FL中新出现的攻击的更多详细信息,以及一些应对此类攻击的最新对策。
Privacy Issues
- 1 Information exploiting attacks in machine learning - A brief overview
- 2 Differential privacy-based protection solutions for FL participants
- 3 Collaborative training solutions
- 4 Encryption-based Solutions
1) Information exploiting attacks in machine learning - A brief overview
最早显示出从经过训练的模型中提取信息的可能性的一项研究是[154]。 在本文中,作者表明,在训练阶段,训练样本中隐含的相关性被收集在训练模型内部。 因此,如果释放训练后的模型,则可能导致攻击者意外泄漏信息。 例如,对手可以从其受过训练的语音识别系统推断出用户的种族或性别。 在[155]中,作者开发了一种模型反演算法,该算法在利用基于决策树或面部识别训练模型的信息中非常有效。 这种方法的思想是将目标特征向量与每个可能的值进行比较,然后得出加权概率估计值,该估计值是正确的值。 实验结果表明,通过使用这种技术,对手可以从其面部标签中非常准确地重建受害者的面部图像。
最近,[156]中的作者表明,对手甚至有可能通过对预测模型的查询来推断受害者的信息。 特别是,当恶意参与者有权对经过训练的模型进行预测查询时,就会发生这种情况。 然后,恶意参与者可以使用预测查询从数据所有者中提取经过训练的模型。 更重要的是,作者指出,这种攻击可以成功地从广泛的训练模型中提取模型信息,例如决策树,逻辑回归,SVM,甚至包括DNN在内的复杂训练模型。 最近的一些研究工作也证明了基于DNN的训练模型针对模型提取攻击的脆弱性[157]-[159]。 因此,这为共享FL中的训练模型的参与者带来了严重的隐私问题。
2) Differential privacy-based protection solutions for FL participants
为了保护DNN训练的参数的私密性,[20]中的作者介绍了一种称为差分私有随机梯度下降的技术,该技术可以在DL算法上有效地实现。 该技术的关键思想是,在将这样的参数发送到服务器之前,通过使用差分隐私保护随机机制[160](例如,高斯机制),在训练后的参数上添加一些“噪声”。 特别是,在正常FL参与者的梯度平均步骤中,使用高斯分布来近似差分私有随机梯度下降。 然后,在培训阶段,参与者不断计算恶意参与者可以利用其共享参数中的信息的可能性。 一旦达到预定义的阈值,参与者将停止其训练过程。 通过这种方式,参与者可以减轻从其共享参数中泄露私人信息的风险。
受此想法启发,[161]中的作者开发了一种方法,可以为参与者提供更好的隐私保护解决方案。 在这种方法中,作者提出了两个主要步骤来处理数据,然后再将经过训练的参数发送到服务器。 特别地,对于每个学习回合,聚集服务器首先选择随机数量的参与者以训练全局模型。 然后,如果选择参与者在学习回合中训练全局模型,则参与者将采用[20]中提出的方法,即在将训练后的参数发送到服务器之前,使用高斯分布向训练后的模型添加噪声。这样,恶意参与者无法通过使用共享全局模型的参数来推断其他参与者的信息,因为它没有关于谁在每个学习回合中参加了培训过程的信息。
3) Collaborative training solutions:
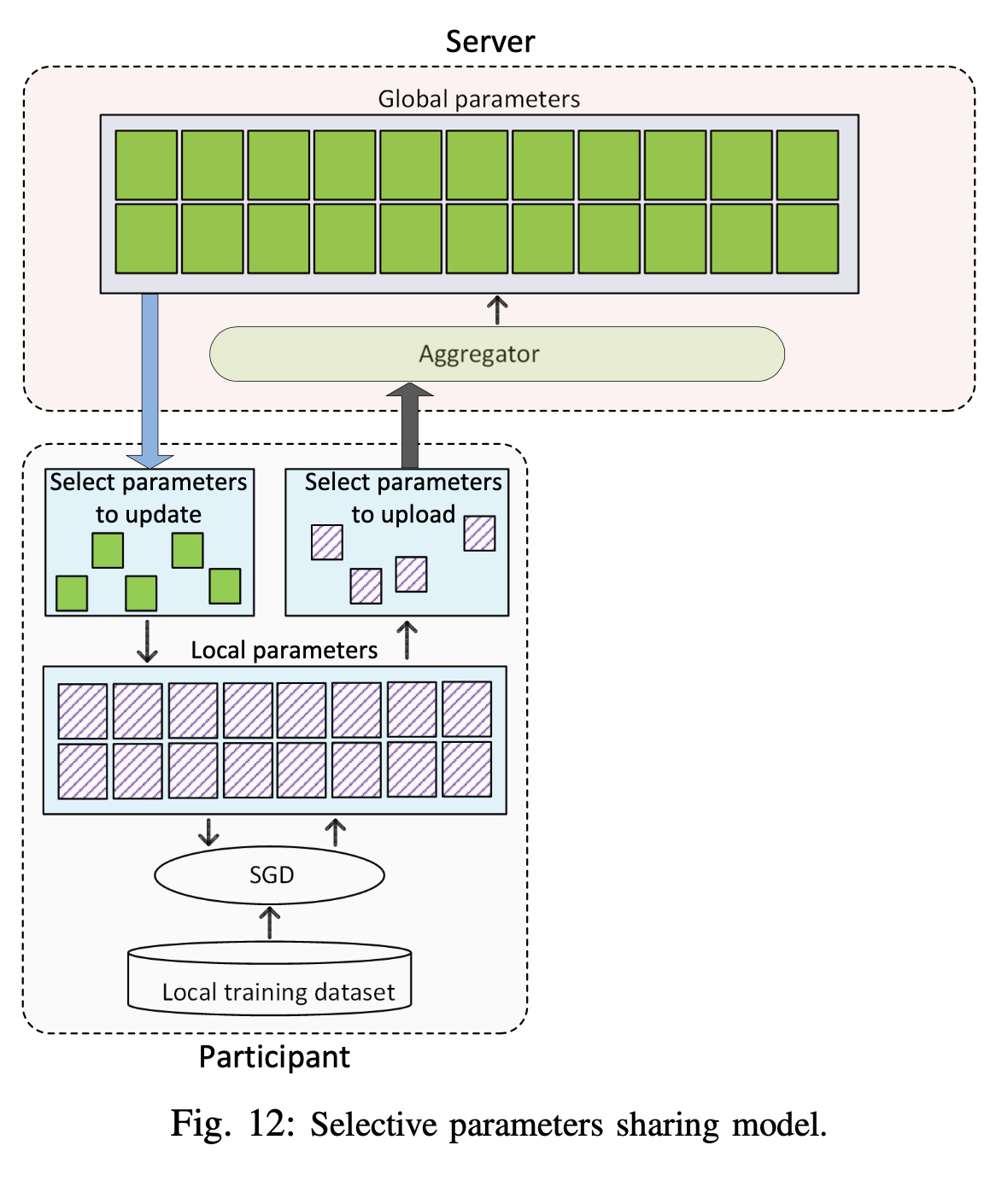
虽然DP解决方案可以保护诚实参与者的私人信息免受FL中其他恶意参与者的侵害,但它们只有在服务器可信任的情况下才能很好地发挥作用。如果服务器是恶意的,则可能对网络中的所有参与者造成更严重的隐私威胁。因此,在[162]中的作者引入了协作DL框架,以使多个参与者可以学习全局模型,而无需将其明确的训练模型上载到服务器。此技术的关键思想是,与其将整个训练后的参数集上传到服务器并将整个全局参数更新到其本地模型,不如每个参与者明智地选择要上传的梯度数量和全局模型中的参数数量如图12所示进行更新。以这种方式,恶意参与者无法从共享模型中推断出显式信息。本文的一个有趣结果是,即使参与者没有共享所有训练过的参数并且没有从共享模型中更新所有参数,所提出的解决方案的准确性仍接近服务器具有所有训练数据集的情况下的准确性。全局模型。例如,对于MNIST数据集[163],当参与者同意共享其参数的10%和1%时,预测模型的准确性分别为99.14%和98.71%,而服务器具有全部训练数据的准确性为99.17%。但是,该方法尚未在更复杂的分类任务上进行测试。
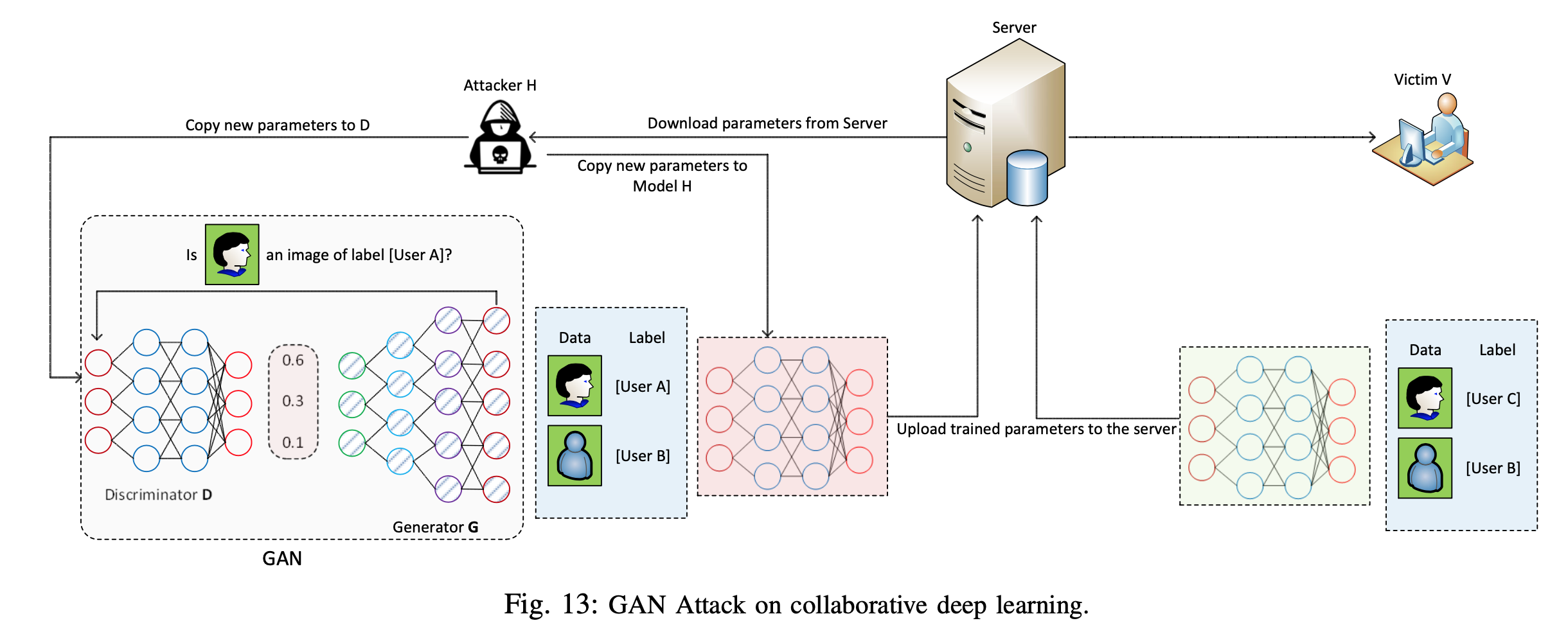
尽管选择性参数共享和DP解决方案可以使利用信息的攻击更具挑战性,但[164]中的作者表明,这些解决方案易受基于通用对抗网络(GAN)开发的新型攻击,称为Powerful Attack[165]。 GAN是一类ML技术,它使用两个神经网络,即生成器网络和鉴别器网络,它们相互竞争以训练数据。生成器网络尝试通过向真实数据中添加一些“噪声”来生成伪造数据。然后,将生成的伪造数据传递到鉴别器网络以进行分类。在训练过程之后,GAN可以生成具有与训练数据集相同的统计数据的新数据。受此想法的启发,[164]中的作者开发了一种强大的攻击,该攻击使恶意参与者甚至可以从受害者那里推断出敏感信息,即使受害人只有一部分共享参数,如图13所示。 GAN攻击[166]中的作者介绍了一种使用秘密共享方案和极端增强算法的解决方案。在每次将新训练的模型以明文形式传输到服务器之前,此方法执行轻量级秘密共享协议。因此,网络中的其他参与者无法从共享模型推断信息。但是,这种方法的局限性是依赖于受信任的第三方来生成签名密钥对。
与上述所有工作不同,[167]中的作者介绍了一种协作培训模型(collaborative training model),其中所有参与者都可以协作来训练联合GAN模型。这种方法的关键思想是,联合GAN模型可以生成可以代替参与者的真实数据的人工数据,从而为诚实的参与者保护真实数据的隐私。特别是,为了保证参与者的数据私密性,同时仍保持训练任务的灵活性,此方法产生了联合生成模型。该模型可以输出特别不属于任何实际用户的人工数据,但来自共同的跨用户数据分布。结果,这种方法可以显着降低从真实数据中恶意利用信息的可能性。但是,这种方法继承了GAN的现有局限性,例如由于生成的虚假数据而导致训练不稳定,这可能会大大降低协作学习模型的性能。
4) Encryption-based Solutions
当参与者想要共享FL中经过训练的参数时,加密是保护参与者数据隐私的有效方法。 在[168]中,引入了同态加密技术,以保护来自诚实但好奇的服务器的参与者共享参数的私密性。 诚实但好奇的服务器定义为希望从参与者的共享参数中提取信息,但将FL中的所有操作保持在正常工作状态的用户。 该解决方案的思想是,在将参与者的训练参数发送到服务器之前,将使用同态加密技术对其进行加密。 这种方法可以有效地保护敏感信息免受好奇的服务器的侵扰,并且可以达到与集中式DL算法相同的准确性。 在[84]中也提出了类似的概念,其中包含用于保护FL参与者信息的秘密共享机制。
尽管[168]和[84]中提出的加密技术都可以防止好奇的服务器提取信息,但它们需要多轮通信,并且不能排除服务器与参与者之间的串通。因此,[169]中的作者提出了一种混合解决方案,该解决方案在FL中集成了加性同态加密和DP。特别是,在将训练后的参数发送到服务器之前,将使用加法同态加密机制以及故意干扰原始参数的加密将它们加密。结果,这种混合方案可以同时防止好奇的服务器利用信息,并解决服务器与恶意参与者之间的串通问题。但是,在本文中,作者没有将所提方法的准确性与没有同态加密和DP的情况进行比较。因此,尚不清楚所提出方法的性能,即就模型准确性而言。
Secure Issues
本篇内容到这里就结束了,欢迎关注公众号《差分隐私》,获取更多前沿技术。


